Comando Linux xz, unxz, xzcat, lzma, unlzma, lzcat
xz , unxz , xzcat , lzma , unlzma e lzcat compressa ou descomprimir .xz e .lzma arquivos.
Descrição
O xz é uma ferramenta de compactação de dados de uso geral com sintaxe de linha de comando semelhante ao gzip e bzip2 . O formato de arquivo nativo é o formato .xz , mas o formato .lzma herdado usado pelo LZMA Utils e os fluxos compactados brutos sem cabeçalhos de formato de contêiner também são suportados.
xz compacta ou descomprime cada arquivo de acordo com o modo de operação selecionado. Se nenhum arquivo for fornecido ou o arquivo for especificado como um traço (” – “), xz lê da entrada padrão e grava os dados processados na saída padrão. O xz recusará (exibirá um erro e pulará o arquivo) para gravar dados compactados na saída padrão, se for um terminal . Da mesma forma, o xz se recusará a ler dados compactados da entrada padrão, se for um terminal.
A menos que –stdout seja especificado, arquivos diferentes de ” – ” são gravados em um novo arquivo cujo nome é derivado do nome do arquivo de origem:
- Ao compactar, o sufixo do formato do arquivo de destino ( .xz ou .lzma ) é anexado ao nome do arquivo de origem para obter o nome do arquivo de destino.
- Ao descompactar, o .xz ou .lzma sufixo é removido do nome do arquivo para obter o nome do arquivo de destino. O xz também reconhece os sufixos .txz e .tlz e os substitui pelo sufixo .tar .
Se o arquivo de destino já existir, um erro será exibido e o arquivo será ignorado.
A menos que grave na saída padrão, xz exibe um aviso e pula o arquivo se qualquer um dos seguintes itens se aplicar:
- O arquivo não é um arquivo regular. Links simbólicos não são seguidos e, portanto, não são considerados arquivos regulares.
- O arquivo possui mais de um link físico .
- O arquivo está definido como setuid , setgid ou sticky bit.
- O modo de operação é definida para comprimir o ficheiro e já tem um sufixo do formato de ficheiro de destino ( .xz ou .txz quando se comprime para o .xz formato, e .lzma ou .tlz quando se comprime para o .lzma formato).
- O modo de operação está definido para descompactar e o arquivo não possui um sufixo de nenhum dos formatos de arquivo suportados ( .xz , .txz , .lzma ou .tlz ).
Após compactar ou descompactar o arquivo, xz copia o proprietário, o grupo, as permissões, o tempo de acesso e o tempo de modificação do arquivo de origem para o arquivo de destino. Se a cópia do grupo falhar, as permissões serão modificadas para que o arquivo de destino não se torne acessível aos usuários que não tiveram permissão para acessar o arquivo de origem. O xz ainda não suporta a cópia de outros metadados, como listas de controle de acesso ou atributos estendidos.
Depois que o arquivo de destino é fechado com sucesso, o arquivo de origem é removido, a menos que –keep tenha sido especificado. O arquivo de origem nunca será removido se a saída for gravada na saída padrão.
O envio de sinais SIGINFO ou SIGUSR1 para o processo xz faz com que as informações de progresso sejam impressas com erro padrão. Isso tem uso limitado, já que quando o erro padrão é um terminal, o uso de –verbose exibe um indicador de progresso com atualização automática.
Uso de memória
O uso da memória do xz varia de algumas centenas de kilobytes a vários gigabytes, dependendo das configurações de compactação. As configurações usadas ao compactar um arquivo determinam os requisitos de memória do descompactador. Normalmente, o descompactador precisa de 5% a 20% da quantidade de memória necessária para o compressor ao criar o arquivo. Por exemplo, descompactar um arquivo criado com xz -9 atualmente requer 65 MiB de memória. Ainda assim, é possível ter arquivos .xz que requerem vários gigabytes de memória para descompactar.
Especialmente usuários de sistemas mais antigos podem achar irritante a possibilidade de uso de memória muito grande. Para evitar surpresas desconfortáveis, o xz possui um limitador de uso de memória embutido, que é desativado por padrão. Embora alguns sistemas operacionais forneçam maneiras de limitar o uso de processos na memória, confiar neles não foi considerado suficientemente flexível.
O limitador de uso de memória pode ser ativado com a opção de linha de comando –memlimit = limit . Freqüentemente, é mais conveniente ativar o limitador por padrão, configurando a variável de ambiente XZ_DEFAULTS, por exemplo, XZ_DEFAULTS = – memlimit = 150MiB . É possível definir os limites separadamente para compactação e descompactação usando –memlimit-compress = limit e –memlimit-decompress = limit . O uso dessas duas opções fora de XZ_DEFAULTS raramente é útil porque uma única execução de xz não pode fazer compactação e descompactação e –memlimit = limit (ou -M limit) é mais curto para digitar na linha de comandos.
Se o limite de uso de memória especificado for excedido ao descompactar, xz exibirá um erro e a descompactação do arquivo falhará. Se o limite for excedido ao compactar, xz tentará reduzir as configurações para que o limite não seja mais excedido (exceto ao usar –format = bruto ou – sem ajuste ). Dessa forma, a operação não falhará, a menos que o limite seja muito pequeno. O dimensionamento das configurações é feito em etapas que não correspondem às predefinições do nível de compactação, por exemplo, se o limite for apenas ligeiramente menor que o valor necessário para xz -9 , as configurações serão reduzidas apenas um pouco, e não para xz -8 .
Concatenando e preenchendo com arquivos .xz
É possível concatenar arquivos .xz como estão. O xz descompactará esses arquivos como se fossem um único arquivo .xz .
É possível inserir preenchimento entre as partes concatenadas ou após a última parte. O preenchimento deve consistir em bytes nulos e o tamanho do preenchimento deve ser um múltiplo de quatro bytes. Isso pode ser útil, por exemplo, se o arquivo .xz for armazenado em uma mídia que mede o tamanho dos arquivos em blocos de 512 bytes.
Concatenação e preenchimento não são permitidos com arquivos .lzma ou fluxos brutos.
Sintaxe
xz [ opção ] ... [ arquivo ] ...
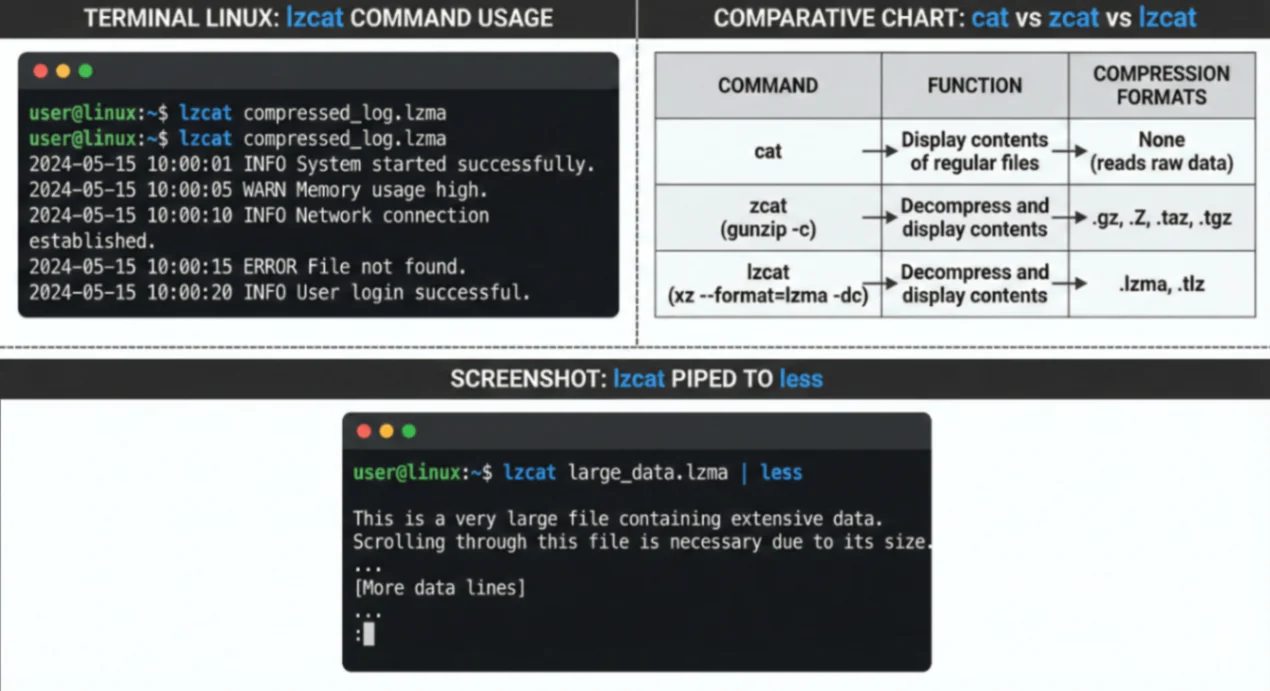
unxz é equivalente a xz – descompress .
xzcat é equivalente a xz –decompress –stdout .
lzma é equivalente a xz –format = lzma .
unlzma é equivalente a xz –format = lzma – descomprimir .
lzcat é equivalente a xz –format = lzma – descompress –stdout .
Opções: modos de operação
Essas opções informam ao xz qual modo usar. Se mais de um modo for especificado, o último entrará em vigor.
| -z , –compress | Comprimir. Esta opção é o modo de operação padrão quando nenhuma opção de modo de operação é especificada e nenhum outro modo de operação está implícito no nome do comando (por exemplo, unxz implica em – descomprimir ). |
| -d , –decompress , –uncompress | Descomprimir. |
| -t , –test | Teste a integridade dos arquivos compactados. Esta opção é equivalente a –decompress –stdout, exceto que os dados descompactados são descartados em vez de gravados na saída padrão. Nenhum arquivo é criado ou removido. |
| -l , –list | Imprima informações sobre arquivos compactados. Nenhuma saída não compactada é produzida e nenhum arquivo é criado ou removido. No modo de lista, o programa não pode ler os dados compactados da entrada padrão ou de outras fontes não observáveis. A listagem padrão mostra informações básicas sobre arquivos, um arquivo por linha. Para obter informações mais detalhadas, use também a opção –verbose . Para obter mais informações, use –verbose duas vezes, mas observe que isso pode ser lento, porque obter todas as informações extras requer muitas buscas. A largura da saída detalhada excede 80 caracteres , portanto, canalizar a saída para, por exemplo, ” less -S ” pode ser conveniente se o terminal não for largo o suficiente. A saída exata pode variar entre as versões xz e diferentes localidades. Para saída legível por máquina, –robot –list deve ser usada. |
Opções: modificadores de operação
| -k , –keep | Não exclua os arquivos de entrada. |
| -f , –force | Esta opção tem vários efeitos: • Se o arquivo de destino já existir, exclua-o antes de compactar ou descompactar. • Compacte ou descompacte, mesmo que a entrada seja um link simbólico para um arquivo comum, tenha mais de um link físico ou o conjunto de bits setuid, setgid ou sticky bit. Os bits setuid, setgid e sticky não são copiados para o arquivo de destino. • Quando usado com –decompress –stdout e xz não pode reconhecer o tipo do arquivo de origem, copie o arquivo de origem como está na saída padrão. Isso permite que o xzcat –force seja usado como cat para arquivos que não foram compactados com o xz . Observe que, no futuro, xzpode suportar novos formatos de arquivos compactados, o que pode fazer com que o xz descomprima mais tipos de arquivos, em vez de copiá-los como na saída padrão. –format = formato pode ser usado para restringir xz para descomprimir apenas um único formato de arquivo. |
| -c , –stdout , –to-stdout | Escreva os dados compactados ou descompactados na saída padrão em vez de em um arquivo. Isso implica – manutenção . |
| – único fluxo | Descompacte apenas o primeiro fluxo .xz e ignore silenciosamente os possíveis dados de entrada restantes após o fluxo. Normalmente esse lixo final faz com que xz exiba um erro. O xz nunca descompacta mais de um fluxo de arquivos .lzma ou fluxos brutos, mas essa opção ainda faz com que o xz ignore os possíveis dados finais após o arquivo .lzma ou fluxo bruto. Esta opção não tem efeito se o modo de operação não for – descomprimir ou – test . |
| –no-sparse | Desative a criação de arquivos esparsos. Por padrão, ao descompactar em um arquivo normal, o xz tenta tornar o arquivo escasso se os dados descompactados contiverem longas sequências de zeros binários . Também funciona ao gravar na saída padrão, desde que a saída padrão esteja conectada a um arquivo regular e certas condições adicionais sejam atendidas para torná-lo seguro. Criar arquivos esparsos pode economizar espaço em disco e acelerar a descompactação, reduzindo a quantidade de E / S do disco . |
| -S. suf , –suffix =. suf | Ao comprimir, use . suf como o sufixo do arquivo de destino em vez de .xz ou .lzma . Se não estiver gravando na saída padrão e o arquivo de origem já tiver o sufixo .suf , um aviso será exibido e o arquivo será ignorado. Ao descompactar, reconheça os arquivos com o sufixo . suf , além de arquivos com o sufixo .xz , .txz , .lzma ou .tlz . Se o arquivo de origem tiver o sufixo . suf , o sufixo é removido para obter o nome do arquivo de destino. Ao compactar ou descompactar fluxos brutos ( –format = bruto), o sufixo sempre deve ser especificado, a menos que seja gravado na saída padrão, porque não há sufixo padrão para fluxos brutos. |
| –files [ = arquivo ] | Leia os nomes dos arquivos para processar a partir do arquivo ; se o arquivo for omitido, os nomes dos arquivos serão lidos a partir da entrada padrão. Os nomes dos arquivos devem ser finalizados com o caractere de nova linha . Um traço (” – “) é usado como um nome de arquivo normal; isso não significa entrada padrão. Se os nomes dos arquivos também forem fornecidos como argumentos da linha de comando, eles serão processados antes da leitura dos nomes dos arquivos . |
| –files0 [ = arquivo ] | Esta opção é idêntica a –files [ = file ], exceto que cada nome de arquivo deve ser finalizado com o caractere nulo. |
Opções: formato básico de arquivo e opções de compactação
| -F formato , –format = formato | Especifique o formato do arquivo para compactar ou descompactar:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -C cheque , –check = cheque | Especifique o tipo da verificação de integridade. A verificação é calculada a partir dos dados não compactados e armazenada no arquivo .xz . Esta opção tem efeito apenas ao compactar no formato .xz ; o formato .lzma não suporta verificações de integridade. A verificação de integridade (se houver) é verificada quando o arquivo .xz é descompactado. Tipos de verificação suportados:
A integridade dos cabeçalhos .xz é sempre verificada com o CRC32. Não é possível alterá-lo ou desativá-lo. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -0 … -9 | Selecione um nível predefinido de compactação. O padrão é -6 . Se vários níveis predefinidos forem especificados, o último entrará em vigor. Se uma cadeia de filtros personalizada já foi especificada, a configuração de um nível predefinido de compactação limpa a cadeia de filtros personalizada. The differences between the presets are more significant than with gzip and bzip2. The selected compression settings determine the memory requirements of the decompressor, thus using a too high preset level might make it painful to decompress the file on an old system with little RAM. Specifically, it’s not a good idea to blindly use -9 for everything like it often is with gzip and bzip2.
On the same hardware, the decompression speed is approximately a constant number of bytes of compressed data per second. In other words, the better the compression, the faster the decompression will usually be. This also means that the amount of uncompressed output produced per second can vary a lot. The following table summarises the features of the presets:
Column descriptions: • DictSize is the LZMA2 dictionary size. It is waste of memory to use a dictionary bigger than the size of the uncompressed file. This is why it is good to avoid using the presets -7 … -9 when there’s no real need for them. At -6 and lower, the amount of memory wasted is usually low enough to not matter. • CompCPU is a simplified representation of the LZMA2 settings that affect compression speed. The dictionary size affects speed too, so while CompCPU is the same for levels -6 … -9, higher levels still tend to be a little slower. To get even slower and thus possibly better compression, see –extreme. • CompMem contains the compressor memory requirements in the single-threaded mode. It may vary slightly between xz versions. Memory requirements of some of the future multithreaded modes may be dramatically higher than that of the single-threaded mode. • DecMem contains the decompressor memory requirements. That is, the compression settings determine the memory requirements of the decompressor. The exact decompressor memory usage is slightly more than the LZMA2 dictionary size, but the values in the table have been rounded up to the next full MiB. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -e, –extreme | Use a slower variant of the selected compression preset level (-0 … -9) to hopefully get a little bit better compression ratio, but with bad luck this can also make it worse. Decompressor memory usage is not affected, but compressor memory usage increases a little at preset levels -0 … -3. Since there are two presets with dictionary sizes 4 MiB and 8 MiB, the presets -3e and -5e use slightly faster settings (lower CompCPU) than -4e and -6e, respectively. That way no two presets are identical.
For example, there are a total of four presets that use 8 MiB dictionary, whose order from the fastest to the slowest is -5, -6, -5e, and -6e. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –fast, –best | These are somewhat misleading aliases for -0 and -9, respectively. These are provided only for backward compatibility with LZMA Utils. Avoid using these options. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –block-size=size | When compressing to the .xz format, split the input data into blocks of size bytes. The blocks are compressed independently from each other. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –memlimit-compress=limit | Set a memory usage limit for compression. If this option is specified multiple times, the last one takes effect. If the compression settings exceed the limit, xz will adjust the settings downwards so that the limit is no longer exceeded and display a notice that automatic adjustment was done. Such adjustments are not made when compressing with –format=raw or if –no-adjust is specified. In those cases, an error is displayed and xz will exit with exit status 1. The limit can be specified in multiple ways: • The limit can be an absolute value in bytes. Using an integer suffix like MiB can be useful. Example: –memlimit-compress=80MiB • The limit can be specified as a percentage of total physical memory (RAM). This can be useful especially when setting the XZ_DEFAULTS environment variable in a shell initialization script that is shared between different computers. That way the limit is automatically bigger on systems with more memory. Example: –memlimit-compress=70% • The limit can be reset back to its default value by setting it to 0, which is currently equivalent to setting the limit to max (no memory usage limit). Once multithreading support is implemented, there may be a difference between 0 and max for the multithreaded case, so it is recommended to use 0 instead of max until the details are decided. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –memlimit-decompress=limit | Set a memory usage limit for decompression. This also affects the –list mode. If the operation is not possible without exceeding the limit, xz displays an error and decompressing the file will fail. See –memlimit-compress=limit for possible ways to specify the limit. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -M limit, –memlimit=limit, –memory=limit | This option is equivalent to specifying –memlimit-compress=limit –memlimit-decompress=limit. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –no-adjust | Display an error and exit if the compression settings exceed the memory usage limit. The default is to adjust the settings downwards so that the memory usage limit is not exceeded. Automatic adjusting is always disabled when creating raw streams (–format=raw). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -T threads, –threads=threads | Specify the number of worker threads to use. The actual number of threads can be less than threads if using more threads would exceed the memory usage limit. Multithreaded compression and decompression are not implemented yet, so this option has no effect for now. |
Custom compressor filter chains
A custom filter chain allows specifying the compression settings in detail instead of relying on the settings associated to the preset levels. When a custom filter chain is specified, the compression preset level options (-0 … -9 and –extreme) are silently ignored.
A filter chain is comparable to piping on the command line. When compressing, the uncompressed input goes to the first filter, whose output goes to the next filter (if any). The output of the last filter gets written to the compressed file. The maximum number of filters in the chain is four, but often a filter chain has only one or two filters.
Many filters have limitations on where they can be in the filter chain: some filters can work only as the last filter in the chain, some only as a non-last filter, and some work in any position in the chain. Depending on the filter, this limitation is either inherent to the filter design or exists to prevent security issues.
A custom filter chain is specified by using one or more filter options in the order they are wanted in the filter chain. That is, the order of filter options is significant! When decoding raw streams (–format=raw), the filter chain is specified in the same order as it was specified when compressing.
Filters take filter-specific options as a comma-separated list. Extra commas in options are ignored. Every option has a default value, so you need to specify only those you want to change.
| –lzma1 [ = opções ], –lzma2 [ = opções ] | Adicione o filtro LZMA1 ou LZMA2 à cadeia de filtros. Esses filtros podem ser usados apenas como o último filtro na cadeia. O LZMA1 é um filtro herdado, suportado quase exclusivamente devido ao formato de arquivo .lzma herdado , que suporta apenas o LZMA1. LZMA2 é uma versão atualizada do LZMA1 para corrigir alguns problemas práticos do LZMA1. O formato .xz usa LZMA2 e não oferece suporte a LZMA1. A velocidade de compressão e as proporções de LZMA1 e LZMA2 são praticamente as mesmas. LZMA1 e LZMA2 compartilham o mesmo conjunto de opções:
Ao decodificar fluxos brutos ( –format = bruto ), o LZMA2 precisa apenas do tamanho do dicionário. O LZMA1 também precisa de lc , lp e pb . | ||||||||||||||||||||||||||||
| –x86 [ = opções ] –powerpc [ = opções ] –ia64 [ = opções ] –arm [ = opções ] –armthumb [ = opções ] –sparc [ = opções ] | Adicione um filtro de ramificação / chamada / salto (BCJ) à cadeia de filtros. Esses filtros podem ser usados apenas como um filtro não-último na cadeia de filtros. Um filtro BCJ converte endereços relativos no código da máquina em seus equivalentes absolutos. Isso não altera o tamanho dos dados, mas aumenta a redundância, o que pode ajudar o LZMA2 a produzir um arquivo .xz 0-15% menor. Os filtros BCJ são sempre reversíveis; portanto, o uso de um filtro BCJ para dados incorretos não causa perda de dados, embora possa piorar um pouco a taxa de compactação. É bom aplicar um filtro BCJ em um executável inteiro; não há necessidade de aplicá-lo apenas na seção executável. A aplicação de um filtro BCJ em um archive que contém arquivos executáveis e não executáveis pode ou não dar bons resultados; portanto, geralmente não é bom aplicar cegamente um filtro BCJ ao compactar pacotes binários para distribuição. Esses filtros BCJ são muito rápidos e usam uma quantidade insignificante de memória. Se um filtro BCJ melhorar a taxa de compactação de um arquivo, ele poderá melhorar a velocidade de descompactação ao mesmo tempo. Isso ocorre porque, no mesmo hardware, a velocidade de descompressão do LZMA2 é aproximadamente um número fixo de bytes de dados compactados por segundo. Esses filtros BCJ têm problemas conhecidos relacionados à taxa de compactação: • Alguns tipos de arquivos que contêm código executável (por exemplo, arquivos de objeto, bibliotecas estáticas e módulos de kernel do Linux) têm os endereços nas instruções preenchidos com valores de preenchimento. Esses filtros BCJ ainda farão a conversão de endereço, o que tornará a compactação pior com esses arquivos. • A aplicação de um filtro BCJ em um arquivo contendo vários executáveis semelhantes pode piorar a taxa de compactação do que não usar um filtro BCJ. Isso ocorre porque o filtro BCJ não detecta os limites dos arquivos executáveis e não redefine o contador de conversão de endereços para cada executável. Ambos os problemas acima serão corrigidos no futuro em um novo filtro. Os antigos filtros BCJ ainda serão úteis em sistemas embarcados, porque o decodificador do novo filtro será maior e consumirá mais memória. Conjuntos de instruções diferentes têm alinhamento diferente:
Como os dados filtrados por BCJ geralmente são compactados com LZMA2, a taxa de compactação pode ser ligeiramente melhorada se as opções de LZMA2 estiverem definidas para corresponder ao alinhamento do filtro BCJ selecionado. Por exemplo, com o filtro IA-64, é bom definir pb = 4 com LZMA2 (2 ^ 4 = 16). O filtro x86 é uma exceção; geralmente é bom manter o alinhamento padrão de quatro bytes do LZMA2 ao compactar executáveis x86. Todos os filtros BCJ suportam as mesmas opções:
| ||||||||||||||||||||||||||||
| –delta [ = opções ] | Adicione o filtro Delta à cadeia de filtros. O filtro Delta pode ser usado apenas como um filtro não-último na cadeia de filtros. Atualmente, apenas o cálculo simples do delta em bytes é suportado. Pode ser útil ao compactar, por exemplo, imagens bitmap não compactadas ou áudio PCM não compactado. No entanto, algoritmos de finalidade especial podem fornecer resultados significativamente melhores que o Delta + LZMA2. Isso é verdade especialmente com o áudio, que comprime mais rápido e melhor, por exemplo, com flac . Opções suportadas:
|
Outras opções
| -q , –quiet | Suprimir avisos e avisos. Especifique isso duas vezes para suprimir erros também. Esta opção não tem efeito no status de saída. Ou seja, mesmo que um aviso tenha sido suprimido, o status de saída para indicar um aviso ainda é usado. |
| -v , –verbose | Seja detalhado . Se um erro padrão estiver conectado a um terminal, xz exibirá um indicador de progresso. A especificação de –verbose duas vezes fornece uma saída ainda mais detalhada. O indicador de progresso mostra as seguintes informações: • A porcentagem de conclusão é mostrada se o tamanho do arquivo de entrada for conhecido. Ou seja, a porcentagem não pode ser mostrada nos tubos. • Quantidade de dados compactados produzidos (compactando) ou consumidos (descompactando). • Quantidade de dados não compactados consumidos (compactados) ou produzidos (descompactados). • Taxa de compactação, calculada dividindo a quantidade de dados compactados processados até o momento pela quantidade de dados não compactados processados até o momento. • Velocidade de compressão ou descompressão. Isso é medido como a quantidade de dados não compactados consumidos (compactação) ou produzidos (descompactação) por segundo. É mostrado após alguns segundos desde que o xz começou a processar o arquivo. • Tempo decorrido no formato M: SS ou H: MM: SS . • O tempo restante estimado é mostrado apenas quando o tamanho do arquivo de entrada é conhecido e já se passaram alguns segundos desde que o xz começou a processar o arquivo. A hora é mostrada em um formato menos preciso, que nunca possui dois pontos, por exemplo, 2 min 30 s. Quando o erro padrão não é um terminal, –verbose fará xzimprima o nome do arquivo, tamanho compactado, tamanho descompactado, taxa de compactação e, possivelmente, também a velocidade e o tempo decorrido em uma única linha para erro padrão após compactar ou descompactar o arquivo. A velocidade e o tempo decorrido são incluídos apenas quando a operação leva pelo menos alguns segundos. Se a operação não foi concluída, por exemplo, devido à interrupção do usuário, também a porcentagem de conclusão será impressa se o tamanho do arquivo de entrada for conhecido. |
| -Q , –no-warn | Não defina o status de saída como 2, mesmo que uma condição que valha um aviso tenha sido detectada. Esta opção não afeta o nível de verbosidade, portanto, –quiet e –no-warn devem ser usados para não exibir avisos e não alterar o status de saída. |
| –robô | Print messages in a machine-parsable format. This is intended to ease writing frontends that want to use xz instead of liblzma, which may be the case with various scripts. The output with this option enabled is meant to be stable across xz releases. See the section ROBOT MODE for details. |
| –info-memory | Display, in human-readable format, how much physical memory (RAM) xz thinks the system has and the memory usage limits for compression and decompression, and exit successfully. |
| -h, –help | Display a help message describing the most commonly used options, and exit successfully. |
| -H, –long-help | Display a help message describing all features of xz, and exit successfully. |
| -V, –version | Display the version number of xz and liblzma in human readable format. To get machine-parsable output, specify –robot before –version. |
Robot mode
The robot mode is activated with the –robot option. It makes the output of xz easier to parse by other programs. Currently –robot is supported only together with –version, –info-memory, and –list. It will be supported for normal compression and decompression in the future.
Robot mode: version
xz –robot –version will print the version number of xz and liblzma in the following format:
XZ_VERSION=XYYYZZZS LIBLZMA_VERSION=XYYYZZZS
Here’s what the version number means, part by part:
| X | Major version. |
| YYY | Minor version. Even numbers are stable. Odd numbers are alpha or beta versions. |
| ZZZ | Patch level for stable releases or a counter for development releases. |
| S | Stability. 0 is alpha, 1 is beta, and 2 is stable. S should be always 2 when YYY is even. |
| XYYYZZZS | Are the same on both lines if xz and liblzma are from the same XZ Utils release. |
Exemplos: 4.999.9beta é 49990091 e 5.0.0 é 50000002 .
Modo de robô: informações de limite de memória
xz –robot –info-memory imprime uma única linha com três colunas separadas por tabulação:
- Quantidade total de memória física (RAM) em bytes
- Limite de uso de memória para compactação em bytes. Um valor especial de zero indica a configuração padrão, que para o modo de thread único é igual a sem limite.
- Limite de uso de memória para descompactação em bytes. Um valor especial de zero indica a configuração padrão, que para o modo de thread único é igual a sem limite.
No futuro, a saída do xz –robot –info-memory pode ter mais colunas, mas nunca mais do que uma única linha.
Modo de robô: modo de lista
xz –robot –list usa saída separada por tabulação. A primeira coluna de cada linha possui uma sequência que indica o tipo de informação encontrada nessa linha:
| nome | Essa é sempre a primeira linha ao iniciar a lista de um arquivo. A segunda coluna na linha é o nome do arquivo. |
| Arquivo | Esta linha contém informações gerais sobre o arquivo .xz . Esta linha é sempre impressa após a linha de nome. |
| corrente | Esse tipo de linha é usado apenas quando –verbose foi especificado. Existem tantas linhas de fluxo quanto o arquivo .xz . |
| quadra | Esse tipo de linha é usado apenas quando –verbose foi especificado. Existem tantas linhas de blocos quanto blocos no arquivo .xz . As linhas de bloco são mostradas após todas as linhas de fluxo; tipos de linhas diferentes não são intercalados. |
| resumo | Esse tipo de linha é usado apenas quando –verbose foi especificado duas vezes. Esta linha é impressa após todas as linhas de bloco. Como a linha do arquivo, a linha de resumo contém informações gerais sobre o arquivo .xz . |
| totais | Essa linha é sempre a última linha da saída da lista. Mostra o total de contagens e tamanhos. |
As colunas das linhas do arquivo são:
- Número de fluxos no arquivo.
- Número total de blocos no fluxo (s).
- Tamanho compactado do arquivo.
- Tamanho não compactado do arquivo.
- Taxa de compressão, por exemplo, 0,123. Se a proporção for superior a 9.999, três traços (—) serão exibidos em vez da proporção.
- Lista separada por vírgula de nomes de verificação de integridade. As seguintes seqüências de caracteres são usadas para os tipos de verificação conhecidos: Nenhum , CRC32 , CRC64 e SHA-256 . Para tipos de verificação desconhecidos, Desconhecido-N é usado, onde N é o ID da verificação como um número decimal (um ou dois dígitos).
- Tamanho total do preenchimento de fluxo no arquivo.
As colunas das linhas de fluxo são:
- Número do fluxo (o primeiro fluxo é 1).
- Número de blocos no fluxo.
- Deslocamento de partida compactado.
- Deslocamento inicial não compactado.
- Tamanho compactado (não inclui preenchimento de fluxo).
- Tamanho não compactado.
- Taxa de compressão.
- Nome da verificação de integridade.
- Tamanho do preenchimento do fluxo.
As colunas das linhas de bloco são:
- Número do fluxo que contém este bloco.
- Número do bloco relativo ao início do fluxo (o primeiro bloco é 1).
- Número do bloco relativo ao início do arquivo.
- Deslocamento inicial compactado em relação ao início do arquivo.
- Deslocamento inicial não compactado em relação ao início do arquivo.
- Tamanho total compactado do bloco (inclui cabeçalhos).
- Tamanho não compactado.
- Taxa de compressão.
- Nome da verificação de integridade.
Se –verbose foi especificado duas vezes, colunas adicionais serão incluídas nas linhas de bloco . Eles não são exibidos com um único –verbose , porque obter essas informações requer muitas buscas e, portanto, pode ser lento:
- Valor da verificação de integridade em hexadecimal.
- Bloquear tamanho do cabeçalho.
- Sinalizadores de bloco: c indica que o tamanho compactado está presente e u indica que o tamanho não compactado está presente. Se o sinalizador não estiver definido, um traço (-) será mostrado para manter o comprimento da string fixo. Novos sinalizadores podem ser adicionados ao final da string no futuro.
- Tamanho dos dados compactados reais no bloco (isso exclui os campos de cabeçalho, preenchimento e verificação).
- Quantidade de memória (em bytes) necessária para descompactar esse bloco com esta versão xz.
- Corrente do filtro. Observe que a maioria das opções usadas no momento da compactação não pode ser conhecida, porque apenas as opções necessárias para descompactação são armazenadas nos cabeçalhos .xz.
As colunas das linhas de resumo são:
- Quantidade de memória (em bytes) necessária para descompactar este arquivo com esta versão xz.
- yes or no indicating if all block headers have both compressed size and uncompressed size stored in them since xz 5.1.2alpha.
- Minimum xz version required to decompress the file.
The columns of the totals line:
- Number of streams.
- Number of blocks.
- Compressed size.
- Uncompressed size.
- Average compression ratio.
- Comma-separated list of integrity check names that were present in the files.
- Stream padding size.
- Number of files. This is here to keep the order of the earlier columns the same as on file lines.
If –verbose was specified twice, additional columns are included on the totals line:
- Maximum amount of memory (in bytes) required to decompress the files with this xz version.
- yes or no indicating if all block headers have both compressed size and uncompressed size stored in them.
- Minimum xz version required to decompress the file.
Exit status
| 0 | Everything was successful. |
| 1 | An error occurred. |
| 2 | Something worthy of a warning occurred, but no errors. |
Environment
xz parses space-separated lists of options from the environment variables XZ_DEFAULTS and XZ_OPT, in this order, before parsing the options from the command line. Note that only options are parsed from the environment variables; all non-options are silently ignored.
| XZ_DEFAULTS | User-specific or system-wide default options. Often this is set in a shell initialization script to enable xz‘s memory usage limiter by default. Excluding shell initialization scripts and similar special cases, scripts must never set or unset XZ_DEFAULTS. |
| XZ_OPT | This is for passing options to xz when it is not possible to set the options directly on the xz command line. This is the case e.g., when xz is run by a script or tool, e.g., GNU tar:XZ_OPT=-2v tar caf foo.tar.xz foo Os scripts podem usar XZ_OPT, por exemplo, para definir opções de compactação padrão específicas do script. Ainda é recomendável permitir que os usuários substituam XZ_OPT se isso for razoável, por exemplo, nos scripts sh, pode-se usar algo como isto: XZ_OPT = $ {XZ_OPT - "- 7e"}; exportar XZ_OPT |
Exemplos
xz foo
Compacte o arquivo foo em foo.xz usando o nível de compactação padrão ( -6 ) e remova foo se a compactação for bem-sucedida.
xz -dk bar.xz
Descomprimir bar.xz em bar e não remova bar.xz mesmo se descompressão é bem sucedida.
tar cf - baz | xz -4e> baz.tar.xz
Crie baz.tar.xz com a predefinição -4e ( -4 –extreme ), que é mais lenta que o padrão -6 , mas precisa de menos memória para compactação e descompactação (48 MiB e 5 MiB, respectivamente).
xz -dcf a.txt b.txt.xz c.txt d.txt.lzma> abcd.txt
Descompacte uma mistura de arquivos compactados e descompactados na saída padrão, usando um único comando.
Comandos relacionados
compactar – Comprime um arquivo ou arquivos.
gzip – Crie, modifique, liste o conteúdo e extraia arquivos dos arquivos zip do GNU.
zip – Um utilitário de compactação e arquivamento.